HTML解析器
前端的核心在于 HTML、CSS 和 JavaScript,这三者共同构成了现代前端技术体系。其中,HTML 作为入口文件通常首先被浏览器请求加载,因此,浏览器渲染页面的首要任务就是解析 HTML 文件。无论浏览器采用何种渲染引擎,都需要遵循 HTML 规范。按照 HTML 解析器的规范,HTML 解析器会将 HTML 字节流转换为 DOM 树,这一过程主要经历了以下步骤:
字节流
当我们访问一个页面时,本质上是完成了一次服务器与客户端之间的交互。在B/S架构中,浏览器作为客户端,通过计算机网络协议与服务器进行数据传输。在计算机网络层面,浏览器首先通过三次握手建立TCP连接,随后基于HTTP协议发送页面请求。服务器接收到请求后进行处理并返回响应,浏览器则负责解析响应内容。在此过程中,页面文件(即HTML文件)被编码成字节流的形式从服务器传输到浏览器。
在上面所述的过程中,HTML文件以字节流的形式传输到浏览器,浏览器第一步的工作是解码字节流,也就是将字节流重新转换成HTML文件源代码,即将字节流转换为字符流。解码前需要确定编码格式,因为不同的编码格式对应不同的字符集。常见的编码格式包括UTF-8、GBK、GB2312等。浏览器会通过一套编码检测机制来确定字节流的编码格式,例如通过HTTP响应头中的`Content-Type`字段获取编码信息。
预处理
在正式处理字符流前需要先对齐进行预处理,预处理的核心流程是规范化换行符(normalize newlines),这是由于不同的操作系统对换行符的定义不同。
| 操作系统 | 换行符 | 说明 |
|---|---|---|
| Linux | \n | 使用 LF(Line Feed,换行符)表示换行。ASCII 编码为 10。 |
| Windows | \r\n | 使用 CRLF(Carriage Return + Line Feed,回车+换行)表示换行。ASCII 编码为 13 和 10 的组合。 |
| macOS (旧版) | \r | 早期的 macOS(基于经典 Mac OS)使用 CR(Carriage Return,回车符)表示换行。ASCII 编码为 13。 |
| macOS (现代) | \n | 现代 macOS(基于 Unix 的 macOS X 及之后版本)与 Linux 一致,使用 LF 表示换行。 |
HTML规范中对规范换行符的操作很简单,主要是以下步骤:
- 替换所有\r\n为\n
- 替换所有的\r为\n
To normalize newlines in a string, replace every U+000D CR U+000A LF code point pair with a single U+000A LF code point, and then replace every remaining U+000D CR code point with a U+000A LF code point.
标记化(词法分析)
在完成字节流的转换与预处理后,HTML解析过程进入了标记化(Tokenization)阶段。标记化类似于编译原理中的词法分析,在此过程中,HTML解析器会将字符流逐步转换为一系列的Token。Token是词法分析的输出结果,是描述HTML文档中基本结构单元。
HTML作为一种具有特定语法规则的语言,其解析依赖于这些规则。例如,一个标准的元素节点总是以<符号开始,并跟随标签名(通常由英文字母组成),接着可以有若干个由空格分隔的属性。若<后紧跟的是!,则这可能表示一个HTML注释或DOCTYPE声明等特殊情况。
整个解析过程通过定义多种状态来实现。每次读取一个字符作为“当前输入字符”,并考虑其后的一个字符作为“下一个输入字符”。依据当前字符的特征,解析器会进入相应状态,并继续检查后续字符,以此类推,直到遇到错误或文件结束符(EOF)。这种机制使得解析器可以在不同状态下灵活切换,确保正确识别各种HTML结构。
以简单的HTML代码示例 <div>1</div> 来说明这一过程:
- 当前输入字符是
<,解析器识别到这是一个标签的开始,进入“开放标签开始状态”; - 将下一个输入字符(即
d)设为新的当前输入字符,准备进一步解析; - 因为当前字符是
d而非!,所以确定这是一个普通标签而非注释,继续读取直至标签名完整,此时已确认为div; - 遇到
>,表明标签定义结束,进入“开放标签结束状态”。由于未发现自闭合标签的形式/>,预期后续应有一个对应的闭合标签; - 接下来读取到数字
1,进入“文本状态”,处理标签内的文本内容; - 再次遇到
<,检查其后的字符为/,判定这是闭合标签的开始,进入“闭合标签开始状态”; - 按照相同逻辑依次处理字符
d,i,v,最终在遇到第二个>时,确认闭合标签解析完毕,进入“闭合标签结束状态”。
最终生成的Token序列如下:
[
{ type: "StartTag", name: "div" }, // <div>
{ type: "Character", data: "1" }, // 1
{ type: "EndTag", name: "div" } // </div>
]树构造(语法分析)
树构造阶段(Tree Construction)的输入是标记化的输出,输出就是文档对象模型DOM树,也就是说树构造阶段其实就是构造DOM树。树构造阶段类似于编译原理中的语法分析。树构造过程通过栈结构(开放元素栈)和状态机动态构建节点间的父子关系,最终形成完整的文档对象模型。
开放元素栈(Open Element Stack)
栈用于跟踪当前未闭合的标签节点。当解析到开始标签Token时,创建对应元素节点并入栈;遇到结束标签Token时,将栈顶元素出栈,完成闭合操作。
插入模式(Insertion Modes)
插入模式 是 HTML 解析器的核心机制之一,它决定了当前解析器处于哪种上下文,从而影响如何处理后续的 Token。插入模式本质上是一个 状态机,不同模式对应不同的 DOM 构建规则。HTML规范定义了12种插入模式(如in body、in table、in head等),用于处理不同上下文环境下的解析规则。例如:<table>标签会触发”in table”模式,确保表格内元素(<tr>、<td>)按特定规则解析;<svg>或<math>标签会切换至”in foreign content”模式,启用XML解析规则。
我们仍然以<div>1</div>为例来说明这树构造过程:
- 解析器接收
TokenStart Tag: <div>,创建一个HTMLDivElement节点,节点入栈(开放元素栈,下同)。 - 解析器接收Token Character: “1”,创建一个内容是1的Text节点,设置为栈顶节点(即前面的HTMLDivElement节点)的子节点。
- 解析器接收
Token End Tag: </div>,栈顶节点出栈。
最终生成的DOM结构如下:
Document
└── html
└── body
└── div
└── "1"优化
HTML解析器在异常处理、性能等方面做了许多优化。
异常兼容机制
HTML解析器具备强大的容错能力,可自动修复常见语法错误。
比如:
- 缺少闭合标签,如
<p><span>123</p> - 嵌套错误,如
<b>1<p>2</b>3</p>
流式处理(Streaming Parsing)
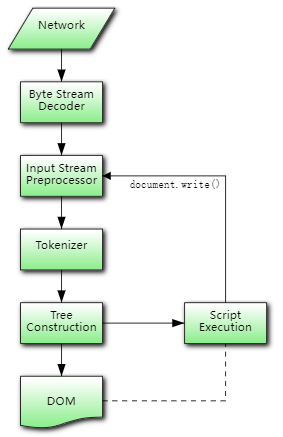
浏览器采用**流式解析**策略:无需等待整个HTML文件下载完成,而是边下载边解析:
- 网络线程持续接收字节流并传递给解析器。
2. 解析器逐块处理Token并构建部分DOM树。
3. 遇到
script标签时暂停 HTML解析,优先加载并执行脚本(除非标记async/defer)。 4. 构建的DOM分片可提前触发渲染,加速首屏显示。
预解析器
HTML 解析器规则中还定义了预测性 HTML 解析器(Speculative HTML parsing),也就是我们常说的预解析器。根据 HTML 规范,每个 HTML 解析器都可以有一个 HTML 预解析器,它会和 HTML 解析器一起工作。
预解析器的主要职责是推测性去加载 HTML 可能需要的资源(如图片、样式表等)。它不仅会在 HTML 解析器正常工作时去推测性的加载资源(例如 HTML 解析器在为 <img 创建 token 时,预加载器就会推测性的加载图像资源),也会在 HTML 解析器被 script 阻塞时,去加载后面可能用到的资源。
User agents may implement an optimization, as described in this section, to speculatively fetch resources that are declared in the HTML markup while the HTML parser is waiting for a pending parsing-blocking script to be fetched and executed, or during normal parsing, at the time an element is created for a token.
通过预加载器,HTML 能够尽快地加载所需要的资源,尤其是在 HTML 解析器被阻塞时(例如遇到Script),可以尽快加载后面的资源,提高渲染速度。
不过需要注意的是,预解析器只会加载文档中的资源。这意味着通过 JS 创建的 <img> 和 <script> 等元素节点所需要加载的资源不会被预解析器加载。
阻塞
Script阻塞
HTML 规范将 script 分为经典Script(classic script) 和模块Script(module script)。
<!-- 经典Script -->
<script> /* 內联js */ </script>
<script scr="xxx"> </script>
<!-- 模块Script -->
<script type="module"> /* 內联js */ </script>
<script scr="xxx" type="module"> </script>经典Script 的加载和执行通常会阻塞 HTML 解析,除非设置了 async 或 async 属性,两种属性导致经典Script的加载方式会变为并行加载,这能避免阻塞 HTML 解析。
模块Script 默认情况下延迟执行,即并行加载,在页面解析完毕后执行,因此手动对模块Script设置 defer 属性是没有任何效果的。如果设置了 async 属性,那么模块Script 则仍然是并行加载,但是会在 Script 可用时立即执行。
| 经典 Script | 加载 | 执行 | 加载是否阻塞 HTML解析 | 执行是否阻塞 HTML解析 |
|---|---|---|---|---|
<script async> | 并行 | 脚本可用时 | ❌ | ✅ |
<script defer> | 并行 | 页面解析完毕后 | ❌ | ✅ |
<script> | 立即 | 脚本可用时 | ✅ | ✅ |
<script type="module"> | 并行 | 页面解析完毕后执行 | ❌ | ✅ |
<script type="module" async> | 并行 | 在可用时立即执行 | ❌ | ✅ |
注意:根据 HTML 规范,浏览器会在脚本可用时就立即执行,而不是必须等到 JS脚本全部加载完毕。
下面示意图对以上内容进行了总结:

StyleSheet 阻塞
HTML规范中明确规定了 HTML 解析器需要如何处理引入外部样式表的 link 元素:
A link element of this type is implicitly potentially render-blocking if the element was created by its node document ‘s parser.
这句话有几个关键术语:
| 术语 | 解释 |
|---|---|
A link element of this type(指具有rel=stylesheet的<link>元素) | 指具有rel=stylesheet的<link>元素(即CSS样式表链接) |
| created by its node document ‘s parser(由node文档解析器创建) | 由 HTML 解析器创建的 Link 元素节点,而不是 JS 动态插入的。 |
| implicitly potentially render-blocking(隐式潜在的渲染阻塞) | 可能(但不一定)阻塞渲染,需要浏览器按规则处理 |
这句话的意思是:当文档解析器在解析HTML时遇到 <link rel="stylesheet"> 元素,这个样式表资源会被视为潜在的渲染阻塞资源,浏览器可能需要暂停渲染直到该样式表加载并解析完成。
此外,[HTML 规范](HTML Standard) 还明确了 stylesheet 阻塞 script 执行的场景,原文如下:
If the style sheet referenced no other resources (e.g., it was an internal style sheet given by a style element with no @import rules), then the style rules must be immediately made available to script; otherwise, the style rules must only be made available to script once the event loop reaches its update the rendering step.
An element el in the context of a Document of an HTML parser or XML parser contributes a script-blocking style sheet if all of the following are true:
- el was created by that Document’s parser.
- el is either a style element or a link element that was an external resource link that contributes to the styling processing model when the el was created by the parser.
- el’s media attribute’s value matches the environment.
- el’s style sheet was enabled when the element was created by the parser.
- The last time the event loop reached step 1, el’s root was that Document.
- The user agent hasn’t given up on loading that particular style sheet yet. A user agent may give up on loading a style sheet at any time.
根据规范,如果没有引用其他资源(例如 @import),那么 style 会立即可用于 script 脚本,否则需要等到事件循环的”更新渲染”阶段才可用。
如果满足下面所有情况,那么 Script 执行将会被阻塞。
| 条件序号 | 必要条件描述 | 示例(满足) | 示例(不满足) |
|---|---|---|---|
| 1 | 由文档解析器创建的元素 | html 中的 style 标签 | js 动态创建的 style 元素节点 |
| 2 | HTML 文档中的 style 标签或 link 标签引入的样式表(rel=“stylesheet”),而不是 JS 动态创建的 | <style>或<link rel="stylesheet" href="a.css"> | <link rel="preload" href="a.css"> |
| 3 | media属性匹配当前环境 | <style> media 属性默认时 auto,与 <style media="auto"> 等价 | <style media="print"> |
| 4 | 样式表已启用 | · <style> | <style disabled> |
| 5 | 属于当前文档 | 未调用 element.remove() | 游离的元素节点 |
| 6 | 浏览器未放弃加载 | 正常加载中的样式表 | 404 或其他错误导致加载失败 |
HTML 解析器的应用
学习HTML解析规范的意义不仅在于了解浏览器内部工作运行方式,更有助于我们了解现代前端框架的底层工作原理,例如Vue的模板语法本质上就是对HTML语法的增强,其底层实现方式是对HTML解析流程的扩展,简要来说由以下几个步骤:
模板语法
↓ (词法分析、语法分析)
Template AST
↓ (transform)
Codegen
↓ (遍历树生成)
渲染函数笔者曾基于对HTML解析规则和Vue模板解析的理解,开发了一款Markdown编译器。其底层工作原理在很大程度上借鉴了上述思想,有兴趣的读者可以深入探究一下。